Finals Revision
Finals Revision
copyright chocolate-lips jk i know nothings
ganbatteyo~~
DISCLAIMER: THINGS IN THIS REVISION SHEET MAY BE WRONG. IF YOU DO SPOT ANYTHING WRONG, PLEASE SCREAM DIRECTLY INTO MY FACE AND I WILL CHANGE IT AS SOON AS I CAN.
ALSO, THIS REVISION SHEET DOES NOT CONTAIN THE INFORMATION BEFORE MIDTERMS. I HAVE A SEPARATE PAGE FOR THAT AT THE LEFT SIDE OF THIS PAGE.
FINALLY, I SCREENSHOTTED THE MOST IMPORTANT SLIDES AND PLACED THEM HERE, BUT PLEASE REMEMBER TO GO THROUGH ALL OF THE SLIDES BEFORE THE EXAM.
Threads
Stack Frame and Introduction
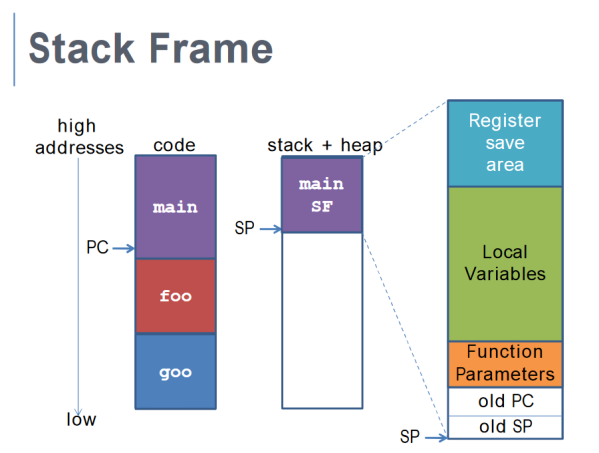 +
+Addresses - Bottom is Low and Top is High
Every function call (subprogram) has its own assigned stack frame, used to store important information.
The Stack Pointer is used to point to the beginning of the stack frame.
- Stack frame is “allocated” by decrementing stack pointer - in other words, its a way for your function to say “I'm using this bit of the stack”. In other words, if an interrupt happens, anything at addresses less (downwards) than the stack pointer are fair game - the OS can wipe it and replace it with other data.
The Program Counter is, to revise, a value stored in the Program Counter Register containing the address of the currently executing instruction.
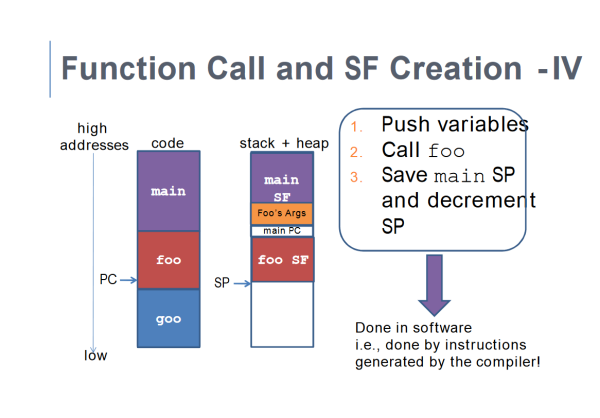
Each function does not have the same stack frame size because of different local variable sizes.
Size of stack frame is determined at compile-time.
Note that there are two kinds of stack - a user stack for user-level programs and a kernel stack used by system-calls.
Multithreading
From our good friend Wikipeda,
In computer architecture, multithreading is the ability of a central processing unit (CPU) or a single core in a multi-core processor to execute multiple processes or threads concurrently, appropriately supported by the operating system.
Remember, this means that the number of threads running concurrently at the same time may not be the same as the number of the cores on the CPU!
Also note that threads are a software concept, not a hardware concept.
Advantages of multithreading:
- Responsiveness
- Resource Sharing (Threads share the resources of the parent threads)
- Economy
- Stability
Common Threading Functions
Header required is <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
if have multiple args, then the args are in a struct of which the pointer is put into pthread_create
it returns 0; on error returns an error number and the contents of the thread are undefined.
int pthread_join(pthread_t thread, void **retval);
Similar usage as wait for forking, in that it waits for a certain thread to terminate.
On success, returns 0, else, returns error.
int pthread_detach(pthread_t thread);
The pthread_detach() function marks the thread identified by thread
as detached. When a detached thread terminates, its resources are
automatically released back to the system without the need for
another thread to join with the terminated thread.
On success, pthread_detach() returns 0; on error, it returns an error
number.
int pthread_cancel(pthread_t thread) is kinda like kill (sends a cancellation request to a thread)
After a canceled thread has terminated, a join with that thread using
pthread_join(3) obtains PTHREAD_CANCELED as the thread's exit status.
(Joining with a thread is the only way to know that cancellation has
completed.)
void pthread_exit(void *retval);
The pthread_exit() function terminates the calling thread and returns
a value via retval that (if the thread is joinable) is available to
another thread in the same process that calls pthread_join(3).
In that way, pthread_exit() is very similar to exit for forking.
Some notes:
- A nice use case of join is - say for example the main() function/thread creates a thread and doesn't wait ( using join ) for the created thread to complete and simply exits, then the newly created thread will also stop!
- You should call detach if you're not going to wait for the thread to complete with join but the thread instead will just keep running until it's done and then terminate without having the main thread waiting for it specifically.
detach basically will release the resources needed to be able to implement join.
- Both windows and linux thread calls MIGHT be tested but linux calls are gonna have more emphasis. If you're super paranoid you're gonna want to look up Windows documentation for multithreading.
Synchronization
Atomicity
From Wikipedia:
In concurrent programming, an operation (or set of operations) is atomic, linearizable, indivisible or uninterruptible if it appears to the rest of the system to occur instantaneously. Atomicity is a guarantee of isolation from concurrent processes. Additionally, atomic operations commonly have a succeed-or-fail definition—they either successfully change the state of the system, or have no apparent effect.
In other words, atomic processes cannot be interrupted by another process, while non-atomic processes can. This is because non-atomic processes, even if, sometimes, they are one instruction, are actually made up of multiple instructions.
This becomes problematic when we discuss...
Critical Sections
Critical Sections are basically shared memory that multiple processes can get to and modify. When multiple processes can interrupt each other while modifying the same piece of memory, of course things will mess up.
This particular mess-up is referred to as a race condition.
EXAMPLE:
This is a little hard to understand, so let's start with an example.
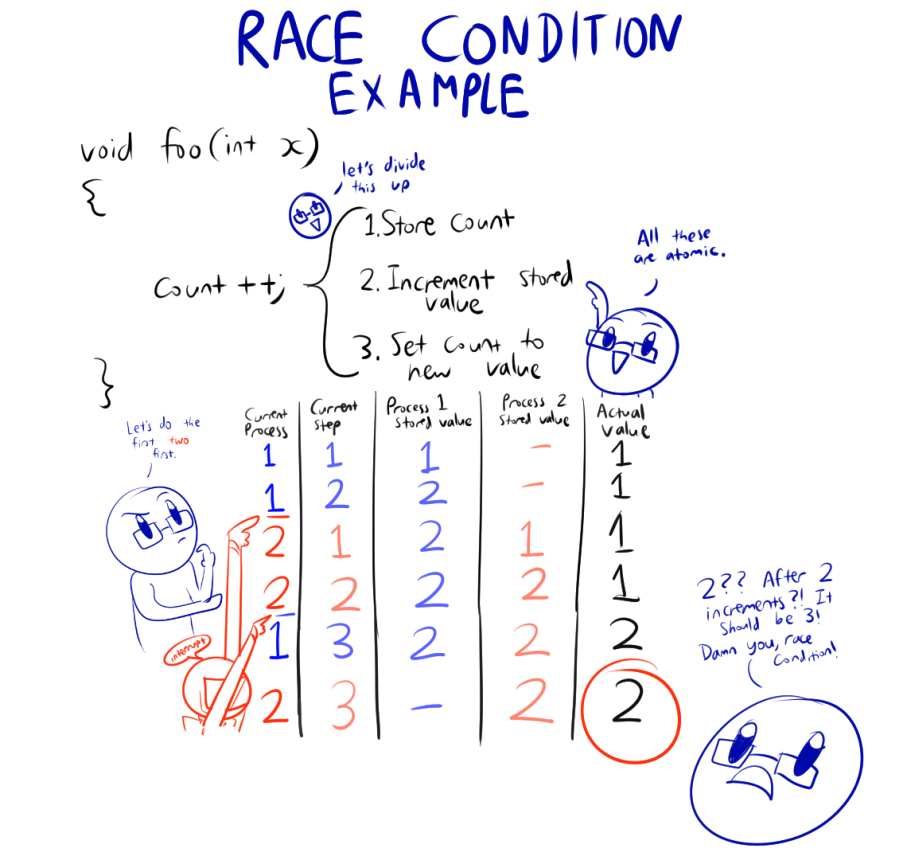
Solution(s)
Critical Sections can't have a bunch of processes modifying it at the same time - but before we get to the solution, let's establish some Solution Criteria. Basically, criteria that needs to be met before the solution can be used.
Solution Criteria
- Criteria
→ Mutual Exclusion
⇒ Once one process enters into critical section, nobody else is allowed in
→ Progress
⇒ When there is no other process entering the critical section selection of the process, selection of the process for processes that are entering into the critical section will not be postponed
⇒ Progress means that process should eventually be able to complete.
→ Bounded Waiting
⇒ Bounded waiting is : There exists a bound, or limit, on the number of times other processes are allowed to enter their critical sections after a process has made request to enter its critical section and before that request is granted.
⇒ To put it another way, Bounded waiting means no process should wait for a resource for infinite amount of time.
- Assumptions
→ Speed independence
⇒ independent of the instruction speed
→ Progress assumed in Critical Section
⇒ Not sure about this one - if someone knows, please message me!
Here is an overview of the basic mechanisms used for the solution; Do note that they are all for achieving the same purpose of locking other processes out.
- No enhanced support
→ Peterson's Algorithm
- Hardware mechanisms
→ TestAndSet and CompareAndSwap
→ Disabling Interrupts (We won't cover this one, it's pretty self-explanatory)
- Operating System Support (software)
→ Semaphores
Note: Since TestAndSet and CompareAndSwap are hardware instructions, they are atomic.
Okay, let's go through the first three - Peterson's Algorithm, TestAndSet and Swap. The code is quite self-explanatory, so I'll just paste it in from Wikipedia, with a few comments to help explain. Note that most of this is obviously not C/C++ - treat it as pseudocode.
Peterson's Algorithm
P0: flag[0] = true;
P0_gate: turn = 1;
while (flag[1] && turn == 1)
{
// busy wait
}
// critical section
...
// end of critical section
flag[0] = false;
P1: flag[1] = true;
P1_gate: turn = 0;
while (flag[0] && turn == 0)
{
// busy wait
}
// critical section
...
// end of critical section
flag[1] = false;
P0_gate: turn = 1;
while (flag[1] && turn == 1)
{
// busy wait
}
// critical section
...
// end of critical section
flag[0] = false;
P1: flag[1] = true;
P1_gate: turn = 0;
while (flag[0] && turn == 0)
{
// busy wait
}
// critical section
...
// end of critical section
flag[1] = false;
TestAndSet

CompareAndSwap

Note that all of these use busy waiting, which results in two problems:
- Low CPU utilization
- Priority Inversion Problem (If Uniprocessor is used) (See below)
Priority Inversion is hard to explain through text, and I think the slides do a good job of explaining it in a visual fashion.
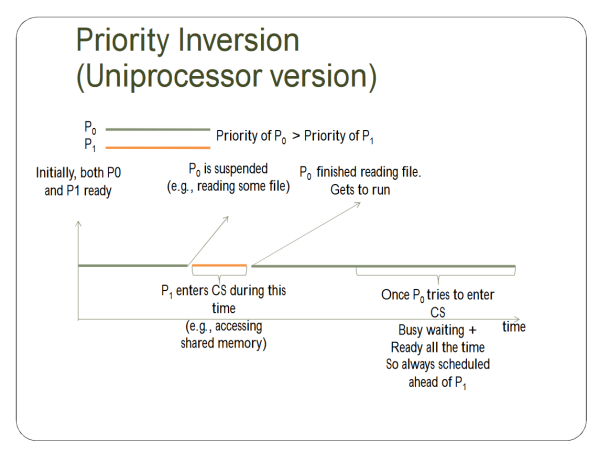
So here's the solution:

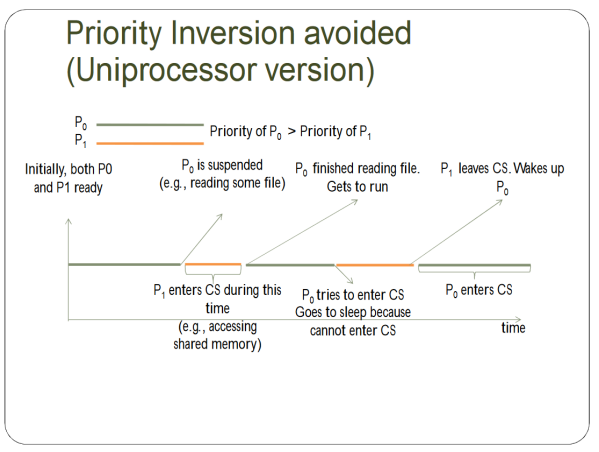
But then ANOTHER PROBLEM COMES UP, OH SNAP.
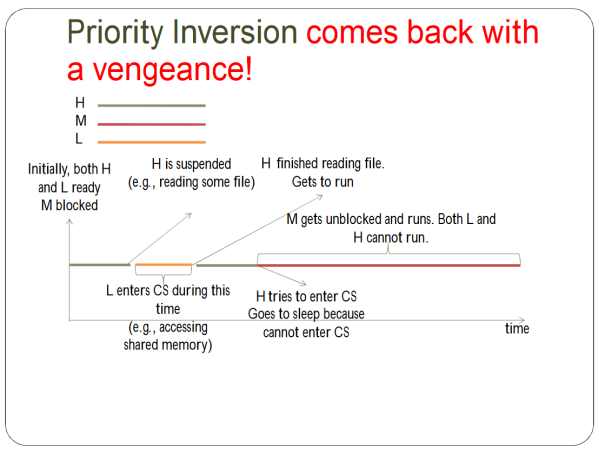
This is fixed by having the L be promoted to the highest possible priority currently requesting CS.
Let's start on Semaphores. But what are Semaphores?
Let's start with the code definition:
class Semaphore
{
void wait ()
{
if(s <= 0)
block process
s--;
}
void signal()
{
s++;
wake up one of blocking process
}
private:
int s;
}
{
void wait ()
{
if(s <= 0)
block process
s--;
}
void signal()
{
s++;
wake up one of blocking process
}
private:
int s;
}
And here's the proper implementation (TestAndSet implementation is up above, if you need it).

The difference between a semaphore and a spinlock is that the semaphore will do context switching when entering CS. Spinlock is therefore better for shorter CS.
A Mutex is a Semaphore, but with the s initialized to 1.
If you're still confused about how to think about Semaphores and Mutexes, here's an analogy that I found useful.
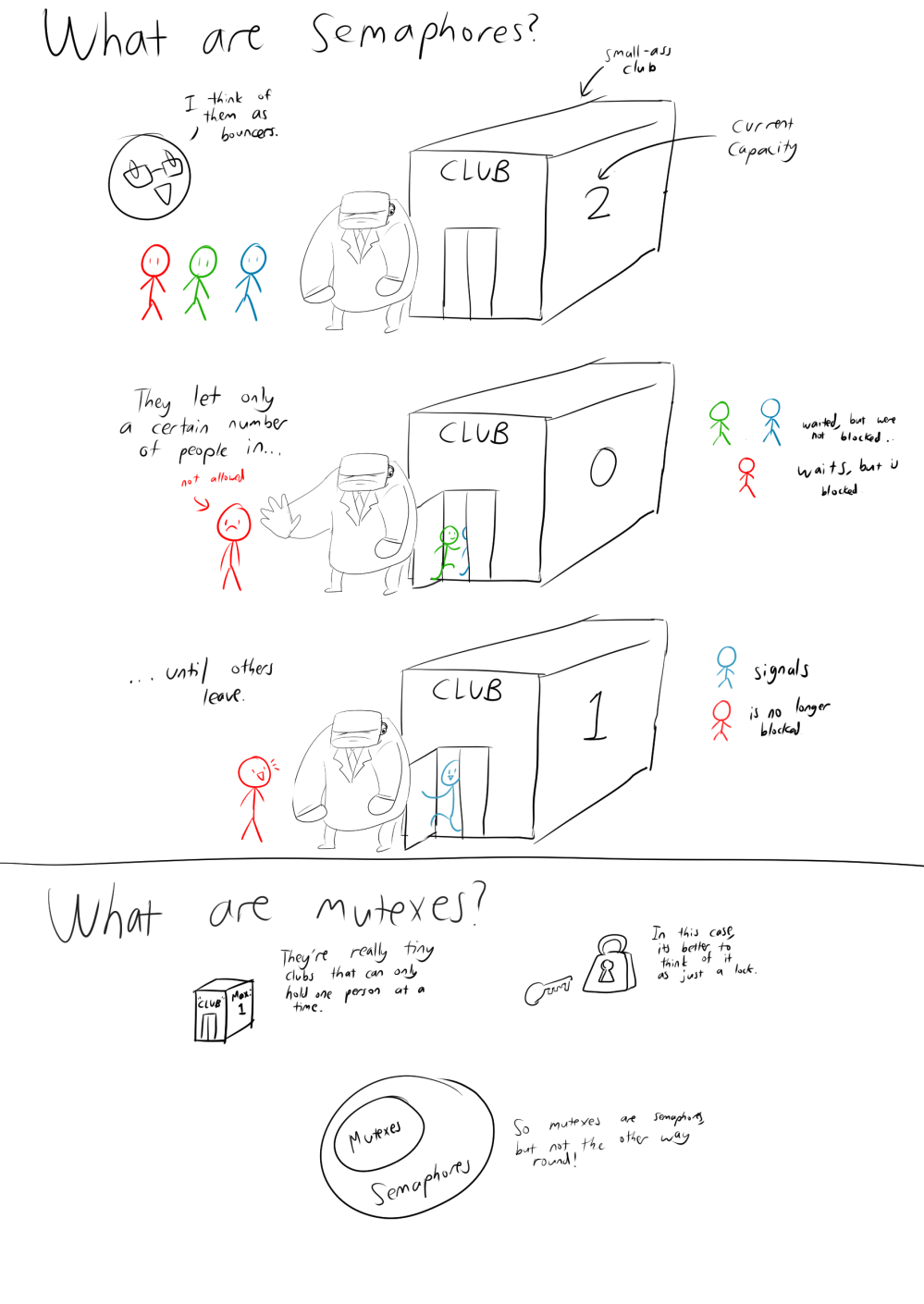
In addition to mutexes, there are also full and empty semaphores - they don't seem to be formal terms, since I can't find anything about them on the 'net. Just something that William uses to make things easier to understand.
Empty sempahores are used to make sure there is something to be produced.
Full semaphores are used to make sure there is something to be consumed.
So Semaphores and Mutexes can solve a bunch of problems, including the Producer-Consumer problem, but let's look at some more practical scenarios.
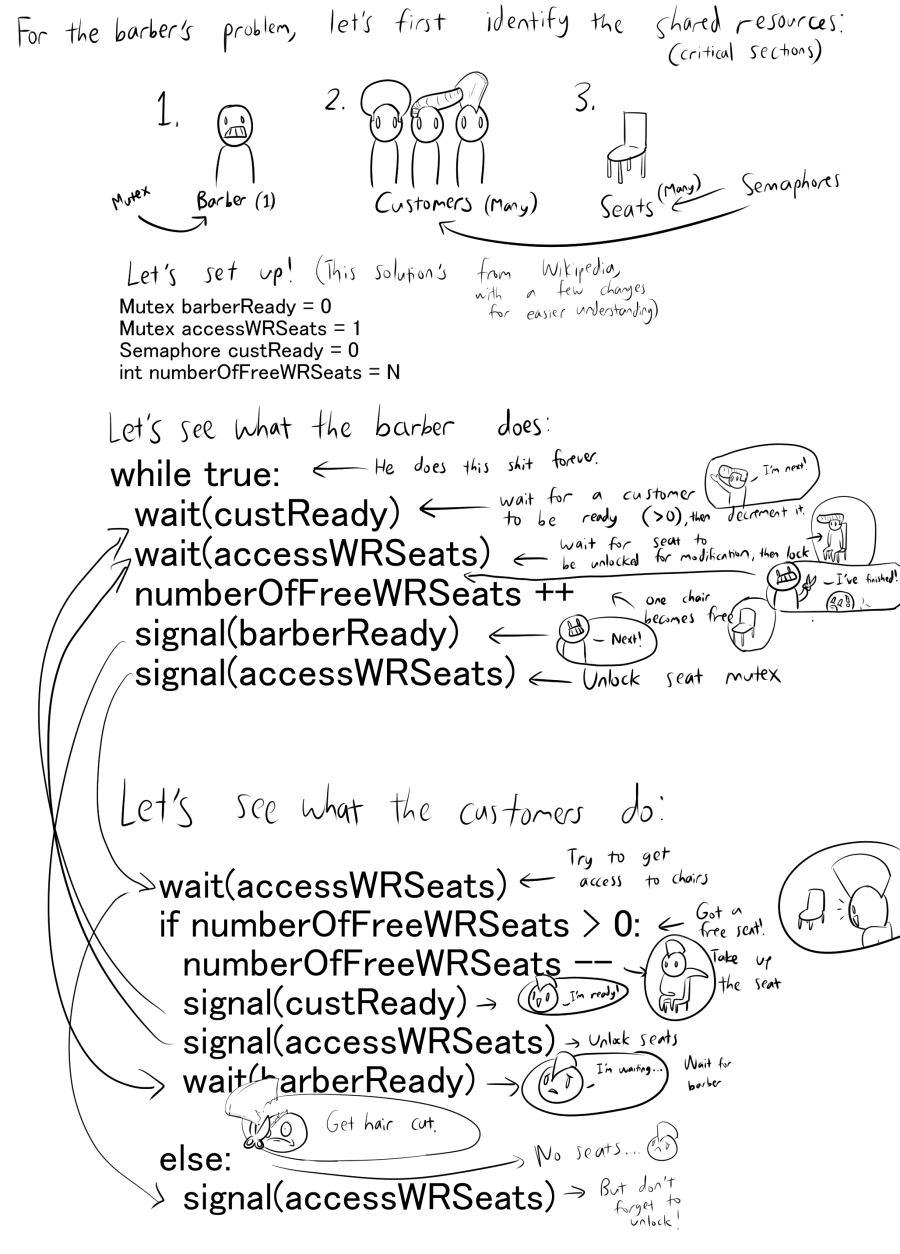
Here's an analysis of the Sleeping Barber problem:
There's also the Dining Philosopher's problem, which I believe is simple enough, but I'll run through a quick explanation.
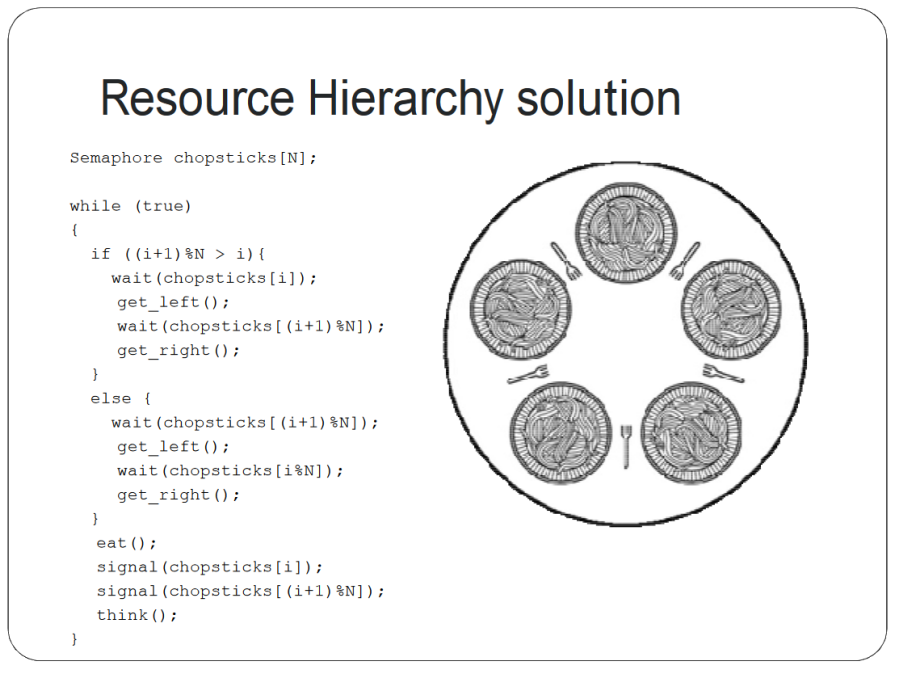
What this does is basically first check if the current i is at the end of the table.
If it isn't, wait for the left fork, then get it. Then wait for the right fork, then get that.
If it is at the end of the table, wait for the RIGHT fork, then get it. Then wait for the LEFT fork, then get that. I'm not sure why the slides say to wait for the right chopstick then get the left - seems like a typo.
Also, don't ask me who the hell eats with two forks, I don't know. Philosophers are crazy as shit, man.
DeadLock and Starvation
Let's finish up with deadlocks. Deadlocks differentiate themselves from a livelock in that in a deadlock, no work is really being done. That's the biggest differentiating factor - but here are some other differences.

Moreover, here's the definition from Wikipedia.
In concurrent computing, a deadlock is a state in which each member of a group of actions, is waiting for some other member to release a lock.
An example of a deadlock from the slides:

Starvation is indefinite blocking. “A process may never be removed from the semaphore queue in which it is suspended."
Priority Inversion we've covered before, but it's a problem along with the other two, so let's go over it again - It's a “scheduling problem when lower-priority process holds a lock needed by higher-priority process”. For more information, look at the relevant slides I pasted in above.
Memory Management
AKA “wtf is going on help”
Address Spaces
Let's start with a question. If I have a program on the computer, and I make it print the address of a variable, and I run that twice concurrently, is it possible that the addresses are the same?
The answer, of course, is YES.
But why? To understand that, we have to cover logical vs physical address spaces.
Logical addresses are “fake” addresses. They have to be translated by a unit called the MCH (Memory Controller Hub, which is part of the CPU) before they can become physical addresses.
Addresses are generated by the CPU during the fetch state when its getting the instruction address from the program counter (although from the memory's point of view, it does not matter).
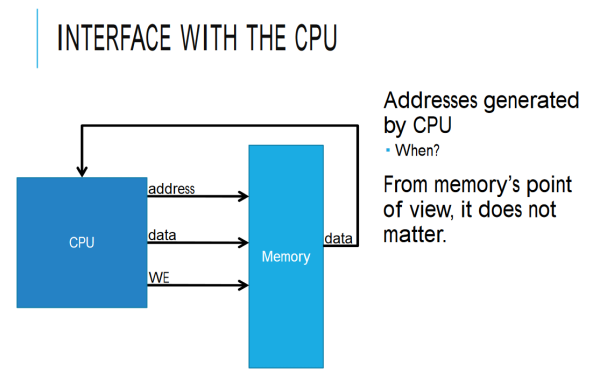
By the way, when he says “address” in this slide, he's actually referring to the address bus. In case you were wondering.
A 32-bit machine can generate addresses between 0 to 2^32-1, 0 included. This means a total of 2^32 addresses.
Remember that all the addresses issued by the CPU outwards are physical addresses!
There are a few ways to bind logical address spaces to physical address spaces
- Compile/Link-Time Binding
→ Logical addresses = Physical addresses
- Load-Time Binding
→ Addresses are relative to some base addresses in physical memory
⇒ (Physical Address) = (Base) + (Logical Address)
→ Programs can be loaded anywhere in physical memory
→ Program can only be loaded if there is a contiguous block of free memory available large enough to hold the program and data
- Execution-Time Binding
→ The physical address is computed in hardware at runtime by the Memory Management Unit (MMU)
⇒ (Physical Address) < (Logical Address)
⇒ The mapping is not necessarily linear (details will be given later)
→ Program may be relocated during execution (even after it is loaded)
→ Program does not require contiguous physical memory
⇒ Used by most modern OS's.
Shared Libraries
Shared Libraries, are, as the name implies, a way to share certain libraries used by a bunch of processes.
They were used to replace Static Libraries - which had problems with duplication in stored and running executables, as well as constant relinking whenever minor bug fixes were made.
The core difference is that shared libraries are linked into an application dynamically, at either load-time (when the executable is load and run) or run-time (after the program has begun to run).
On Windows, shared libraries are normally manifested in the form of .dll files, which are short for Dynamic Link Libraries.
Address Spaces and Naive Solution
Let's have a naive implementation of the logical to physical address translation to start with.
if(Logical Address<limit) //NOTE THAT IT'S < not <=
Physical Address = Base + Logical Address
else
Cause a fault
Physical Address = Base + Logical Address
else
Cause a fault
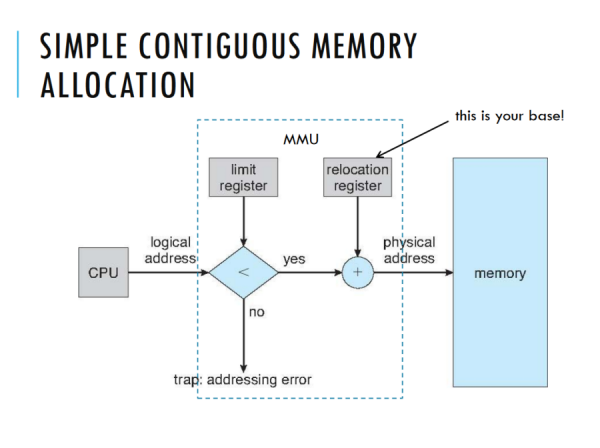
What does the Kernel use?
Kernel “turns off” translation by setting the base to 0 and the limit to the maximum memory size. So it, in effect, uses physical address space.
What is associated with being run by the kernel is usually Operating System code.
Remember, processes can ONLY use logical address spaces!
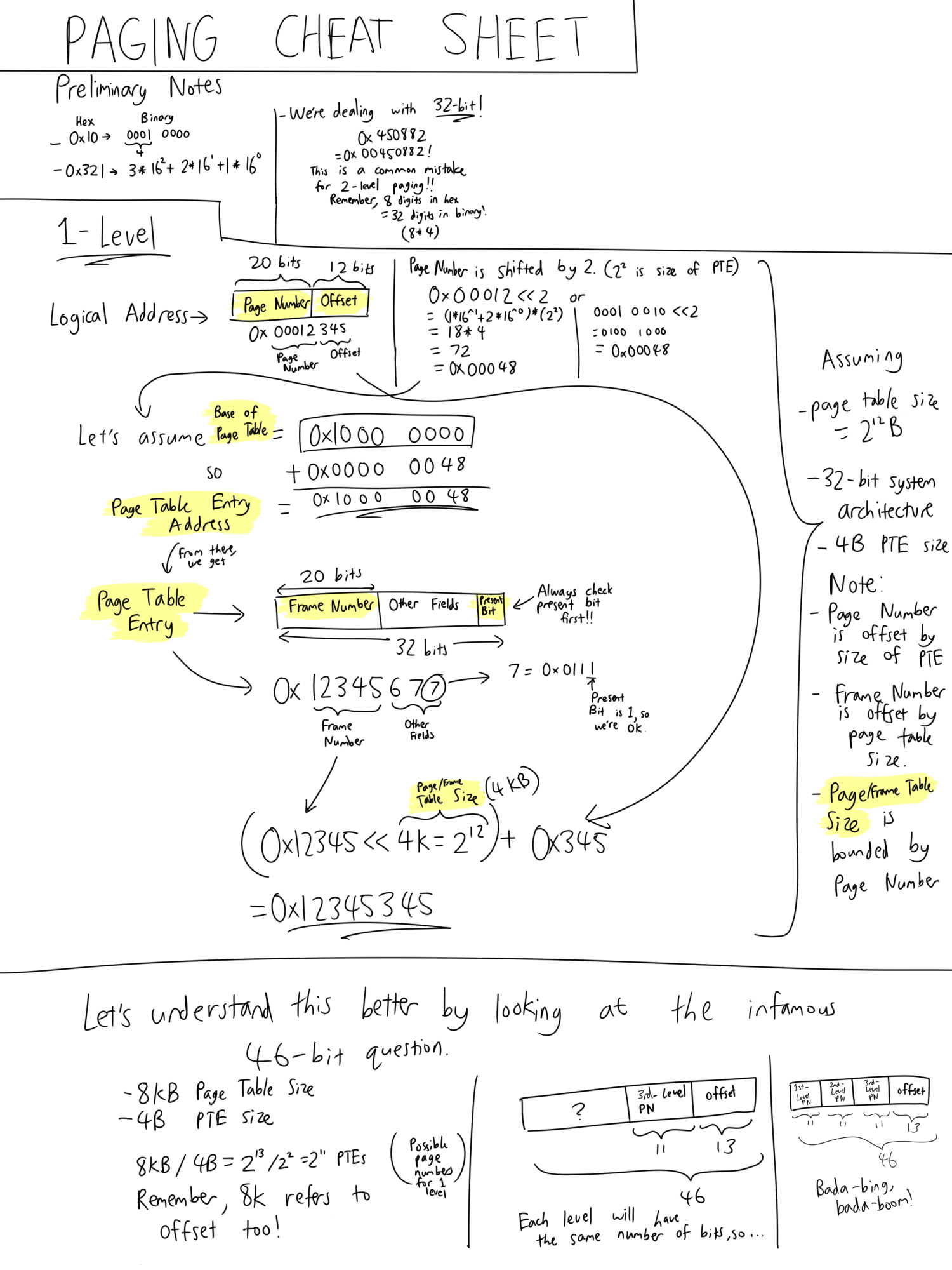
NOTE: FROM TRANSLATION LOOKASIDE BUFFER ONWARDS, IT WILL BE VERY SIMILAR TO SLIDES AS THERE IS NOT MUCH TO FURTHER EXPLAIN. THIS STUFF IS STILL IMPORTANT, ESPECIALLY PAGE REPLACEMENT.
Translation Lookaside Buffer
Cache of page numbers to physical addresses residing within the MMU.
A cache miss will result in a lookup.
It's flushed with every context switch.
Virtual Memory Space
We allow logical memory size to exceed the physical memory size.
Pages and frames are added to the page table as needed.
When physical memory has been exceeded, frames are SOMETIMES written (temporarily) to the hard disk to free up physical memory.
Swap space is used for writing frames: a contiguous block of disk space is set aside for this purpose.
Freeing Physical Memory
Some terms to remember:
Swapping is swapping out an entire process from physical memory to disk.
Paging is having a single page of physical memory to disk. (Several contiguous pages may be written to the disk at one time.)
These two are expensive (in terms of time), so they should be minimized.
Demand Paging
AKA Lazy Swapping
A page in virtual memory is assigned a physical frame only when memory within that page is accessed. (Hence, “Demand” Paging)
Each entry in the page table contains a bit (flag) to mark the page - 1 means it has been assigned a physical frame, 0 means it hasn't.
When a location in logical memory is acessed, the validity bit of the corresponding page is examined.
- If valid, process execution continues as per normal
- If invalid, page fault occurs.
→ The OS finds a free frame in phyiscal memory
→ The desired page is read into the new frame
→ The page table is updated with the new page information, and of course, the validity bit is set to valid
→ Process execution is resumed
Page Replacement
When a page fault occurs, but there are no free physical memory frames:
- A victim frame is chosen - this frame will be paged out (written to disk)
- The page that caused the fault will be assigned to the victim frame and read in
Optimization: a page that has not been modified since it was first read in (such as a code segment) need not be saved to disk (it is already there) - only the validity bit needs to be changed
- In this case, the dirty bit indicates whether it has been modified.
Page Replacement Algorithms
(IMPORTANT!)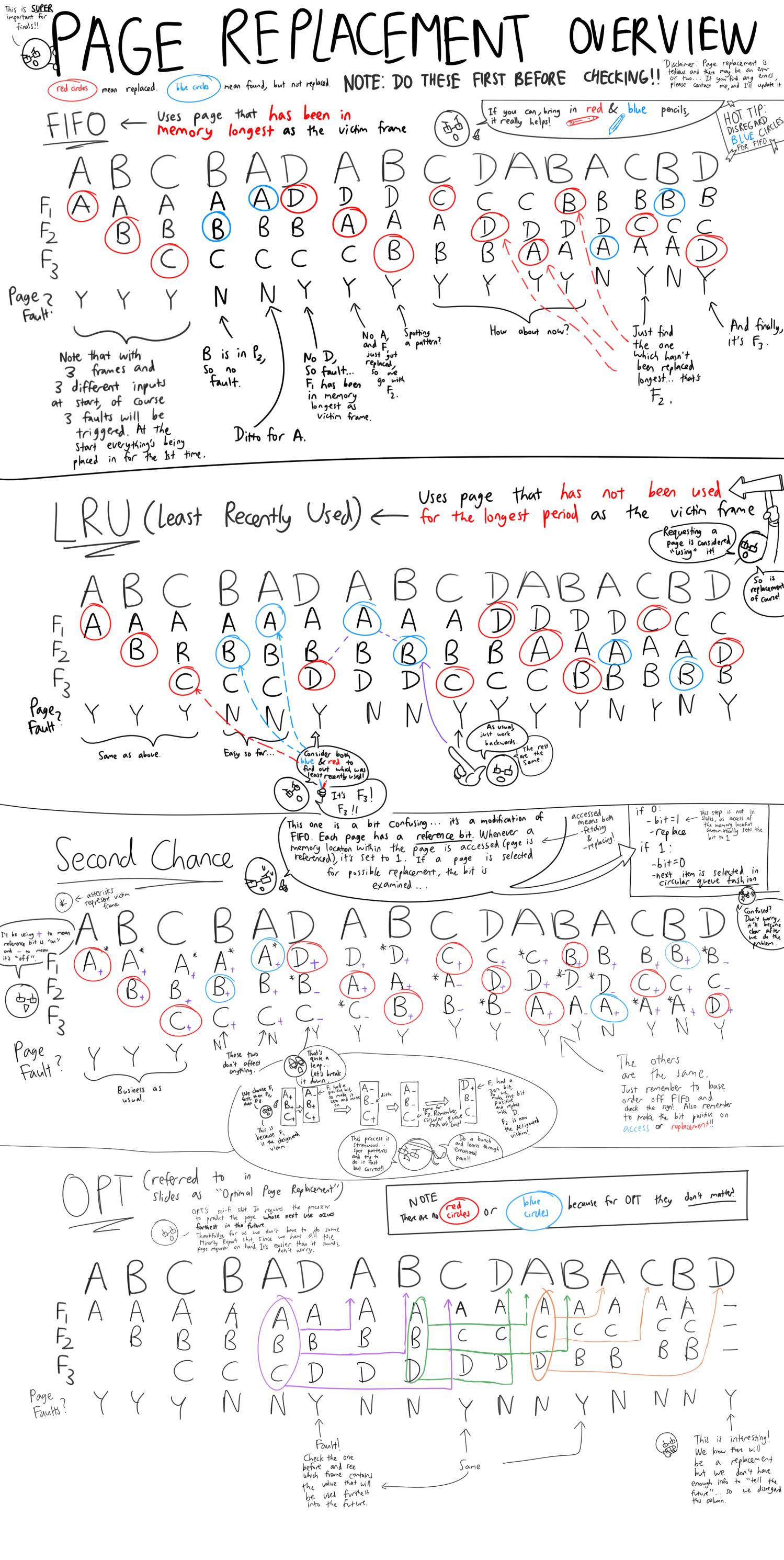
FIFO (First In, First Out) Page Replacement
- This page replacement algorithm chooses the page that has been in the physical memory for the longest as the victim frame.
- It is easy to implement using a queue
- Usually not optimal - more than the minimum number of page faults will usually occur.
Stuff to Watch Out For in Finals
- A 32-bit machine can generate addresses between 0 to 2^32-1, 0 included. This means a total of 2^32 addresses.
- If Process 1 can hold 100k addresses, the logical address space will be from 0 to 100k-1
- Know how many bits 1k has - remember that 1024 is 2^10!
- For scheduling, wait time does not include I/O time!! Remember that wait time is HOW LONG ITS IN READY.
→ While we're at it, Turnaround time is everything. From the moment it enters ready queue to its termination.
→ Response time is just I/O
- To find minimum number of pages, for heap, remember to take into account how much is dynamically allocated
→ For stack, remember that stack grows downwards. Pick the lowest.
→ BE PRUDENT ABOUT WHEN TO ADD 1. Usually, address spaces dont require it.
- This is how the revised semaphores work for wait()
→ while(TestAndSet(&lock) //Lock the shared resource (queue) with a testandset.
→ if(s<=0) //If the semaphore does not have the capacitiy
→ add self to queue; lock = false; block(&lock); //add self to queue, unlock queue resource, sleep
→ else //if semaphore does have capacitiy
→ s--; lock = false; //decrement the capacity and unlock the shared queue
- This is how the revised semaphores work for signal()
→ while(TestAndSet(&lock)); //lock the shared resource (queue) with a testandset
void wait()
{
while(TestAndSet(&lock)); //Lock the shared resource (queue) with a testandset.
if(s<=0) //If the semaphore does not have the capacitiy
{
//add self to queue, unlock queue resource, sleep
add self-process to queue;
lock=false;
block(&lock):
}
else //if semaphore does have capacitiy
{
//decrement the capacity and unlock the shared queue
s--;
lock=false;
}
}
{
while(TestAndSet(&lock)); //Lock the shared resource (queue) with a testandset.
if(s<=0) //If the semaphore does not have the capacitiy
{
//add self to queue, unlock queue resource, sleep
add self-process to queue;
lock=false;
block(&lock):
}
else //if semaphore does have capacitiy
{
//decrement the capacity and unlock the shared queue
s--;
lock=false;
}
}
void signal()
{
while(TestAndSet(&lock)); //Lock the queue
s++;//Increase capacity
if( queue not empty ) //If the queue is not empty, wake someone up
wake up any process waiting in queue
lock = false; //unlock shared queue
}
{
while(TestAndSet(&lock)); //Lock the queue
s++;//Increase capacity
if( queue not empty ) //If the queue is not empty, wake someone up
wake up any process waiting in queue
lock = false; //unlock shared queue
}
- Non-preemptive schedules only when
→ A process terminates
→ A process goes into waiting state
- Preemptive schedules also when
→ A hardware interrupt arrives
→ Process goes from waiting to ready state
→ Process goes from running to ready state